FVP is a novel 3D point cloud representation learning pipeline for robotic manipulation.
General visual representations learned from web-scale datasets for robotics have achieved great success in recent years, enabling data-efficient robot learning on manipulation tasks;
yet these pre-trained representations are mostly on 2D images, neglecting the inherent 3D nature of the world. However, due to the scarcity of large-scale 3D data, it is still hard to extract a universal 3D representation from web datasets. Instead, we seek for a general visual pre-training framework that could improve all 3D representations as an alternative. Our framework, called FVP , is a novel 4D Visual Pre-training framework for real-world robot learning. FVP frames the visual pre-training objective as a next-point-cloud-prediction problem, models the prediction model as a diffusion model, and pre-trains the model on in-domain task datasets directly.
Across twelve real-world manipulation tasks, FVP boosts the average success rate of 3D Diffusion Policy (DP3) for these tasks by 28\%. The FVP pre-trained DP3 achieves state-of-the-art performance across imitation learning methods. Moreover, the efficacy of FVP adapts across various point cloud encoders and datasets. Finally, we apply FVP to the RDT-1B, a larger Vision-Language-Action robotic model, enhancing its performance on various robot tasks.
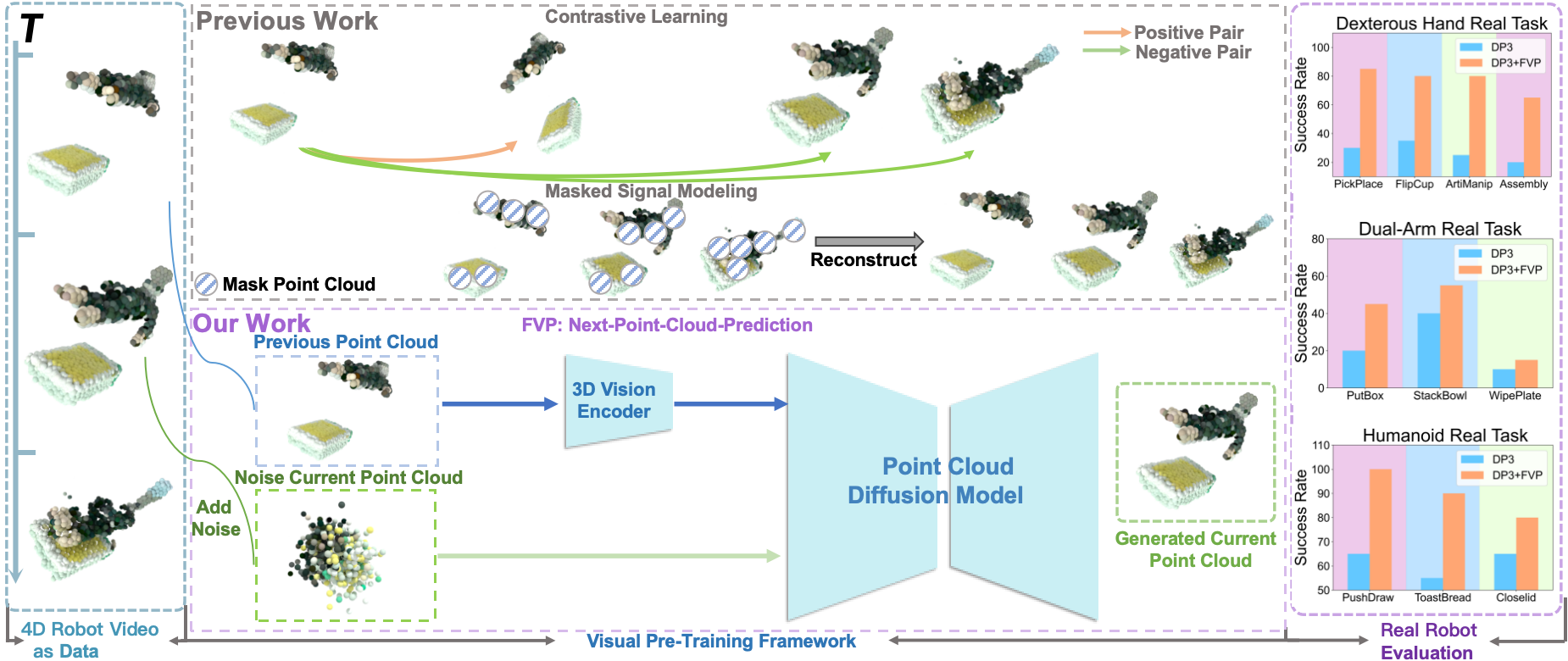
Different from prior works in Contrastive Learning, Masked Signal Modeling; FVP trains 3D visual representations by leveraging the preceding frame point cloud and employing a diffusion model to predict the point cloud of the current frame.

UR5 Dexterous Hand: UR5 single-arm is equipped with a LeapHand dexterous hand to complete four tasks: PickPlace, FlipCup, Assembly, Artimanip.

AgileX Dual-arm: We use the AgileX Cobot Magic dual-arm robot to perform the three manipulation tasks: PutBox, StackBowl, WipePlate.

TianGong Humanoid: We use the TianGong humanoid robot, equipped with built-in cameras and a 30-DoF upper body, to perform three real-world tasks: PushDraw, ToastBread, CloseLid.
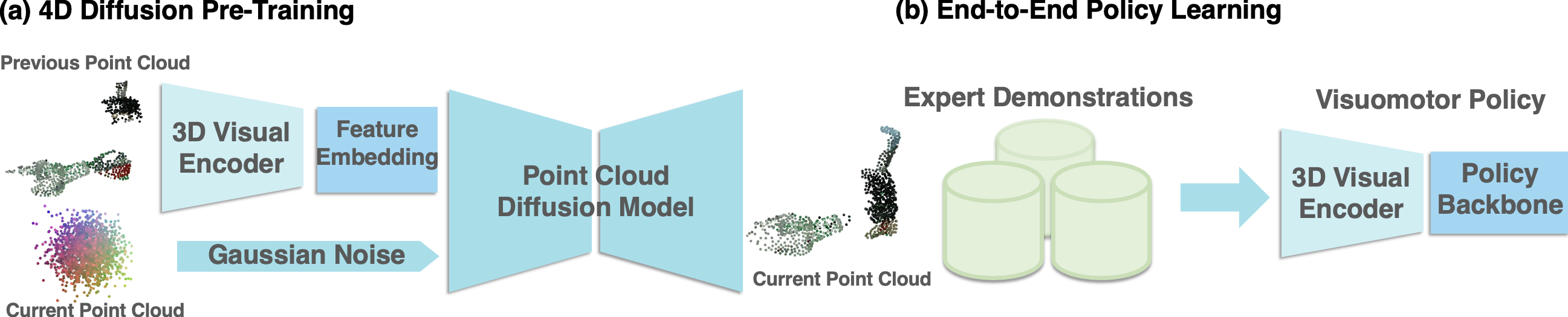
Model Overview
FVP mainly consists of two parts: a 3D visual encoder and a point cloud diffusion model. The 3D visual encoder transforms the point cloud at time step t into the latent visual representation, and the diffusion model uses the latent visual representation and robotic actions to predict the point cloud at step time t+1. During the policy learning stage, we train the pre-trained visual model and the policy backbone jointly.
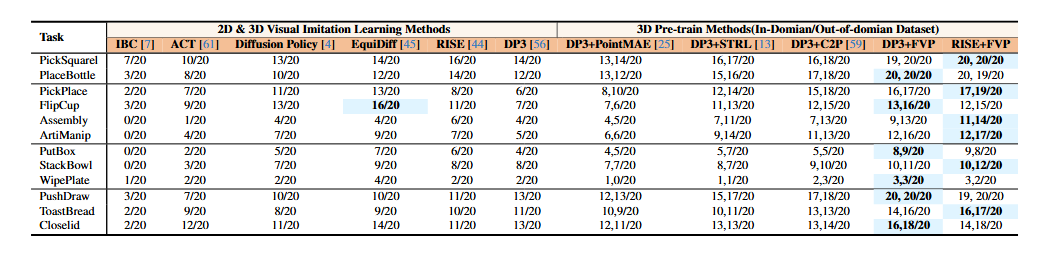
"DP3+FVP" and "RISE+FVP" denote the application of FVP to pretrain the visual models from DP3 and RISE, respectively. "DP3" indicates that the visual model within DP3 has not undergone pretraining. "DP3+PointMAE", "DP3+STRL", and "DP3+C2P" signify the utilization of PointMAE, STRL, and C2P to pre-train the visual model from DP3. The numbers before the comma represent the performance using in-domain datasets for pre-training, while the numbers after the comma represent the performance using out-of-domain datasets (RoboMind) for pre-training.
PutBox
RDT
RDT+FVP
StackBowl
RDT
RDT+FVP
WipePlate
RDT
RDT+FVP
Long-horizon Task
RDT
RDT+FVP
@article{cheng2025fvp,
author = {Chengkai Hou and Yanjie Ze and Yankai Fu and Zeyu Gao and Yue Yu and Songbo Hu and Shanghang Zhang and Huazhe Xu},
title = {FVP: 4D Visual Pre-training for Robot Learning},
journal = {ICCV},
year = {2025},
}